Series 1: Hotstar Autoscaler built with Azure OpenAI

1 About this blog
We have all seen enough posts about Game Changer 😅 plugins built on top of the GPT models. I can assure you this won’t be just another one of those. Join with me in this series to learn about some cool stuffs that you can built using these models in your real-time applications. ( Definitely not a Game Changer! 😉 ).
The objective of this blog is to
- Stimulate fresh ideas by exploring the logical and reasoning capabilities of GPT models with Azure OpenAI.
- Ensure anyone from a development background should be able to follow along the entire series. (I’m not a Data Scientist myself😉 )
2 Have you watched Hotstar scaling architecture video? 🖐️
I assume most of us would have watched this video, where Gaurav Kamboj, Cloud Architect at Hotstar, explains why traditional autoscaling doesn’t work for Hotstar. and shared with us how Hotstar created a global record for live streaming to 25.3 million concurrent viewers.
Well this is gonna be our problem statement for this entire series. While their is no doubt that hotstar’s custom autoscaler is perfectly working fine, our objective here is to expand upon the problem they initially addressed and explore how GPT models could offer innovative solutions for these unique use cases.
3 How hotstar approached this problem with custom autoscaler?
- Trafic based scaling for those services that exposes metrics about number of requests being processed
- Ladder based scaling for those services that didn’t expose these metrics
Hotstar defined those scaling ladder configurations as below,

For more details refer to this blog : https://blog.hotstar.com/scaling-for-tsunami-traffic-2ec290c37504
4 How we are going to approach this problem with Azure OpenAI
4.1 Traffic spikes during IND vs NZ 2019!
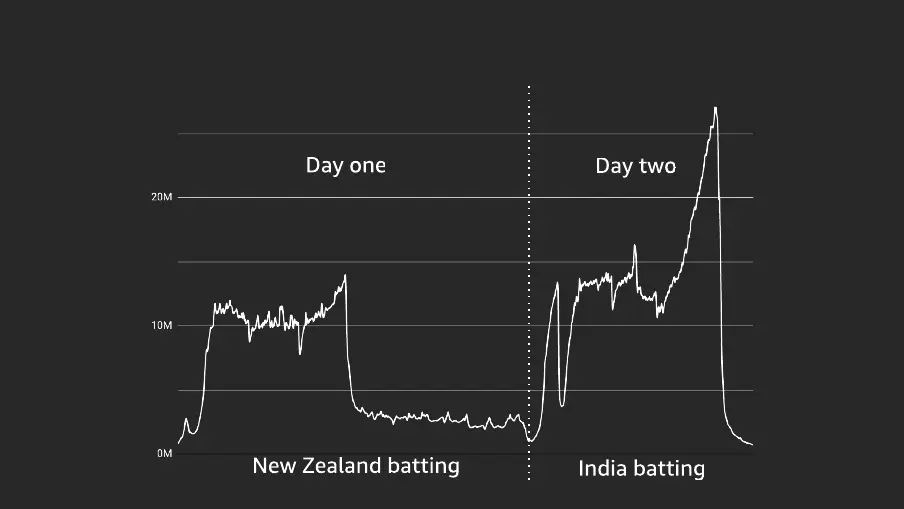
Some of the key observations in the above chart
- Unusual spikes happens based on the sentiments of the viewers
- On day two, when Dhoni came to bat it raisd live users concurrency from 16M to 25M+ users
- After the fall of his wicket , there is a sudden drop in the traffic ( 25M to 1M users)
What if these sentiments are tracked by our GPT models and sent a signal to increase or decrease the instance of services.
4.2 Architecture
Let’s understand different components of this archiecture
- For simplicity, I have considered 3 services for Hotstar application.
- Commentary Service : For simulating the commentary in a gap of 1 minute for each ball, I have created a Azure Durable function which picks each commentary in a gap of 1 minute and push those messages to a Azure service bus queue
- Video service : Video service is for streaming the live game and for that I have created a Virtual machine scale set. Steady and spikes of traffic is common in this service as it is based on the sentiment of the game.
- Recommendation service : Same as video service , we have virtual machine scale sets for recommendation service, that gets triggered when everyone tries to press back button or come to home screen after a key player wicket has been taken
- Azure Cosmos DB : I have created 2 containers ipl_match to hold the ipl_match and ipl_scaling_ladder to hold the scaling ladder configuration
- Azure Prompt flow: We deploy the prompt flow as a real-time endpoint and consumed in Azure Logic app
- Azure Logic app acts as a Prompt flow invoker and based on the output dynamically changes the instance count of video service and recommendation service
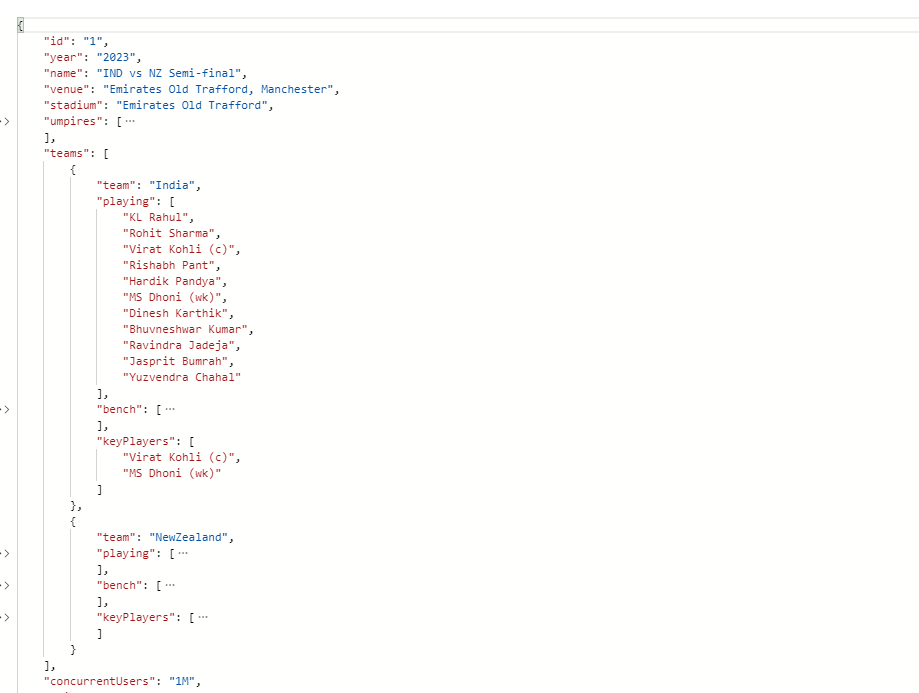

We have loaded the match details for Ind vs NZ in ipl_match container. It contains the Playing XII details along with key players defined for this particular match which is then used in our prompt. This container also contains the number of concurrent users
4.3 DataFlow
- First we will simulate the commentary of the match through our Commentary Service (Azure Durable Functions) that pushes the message to Azure service bus queue at a gap of 40 sec interval.
- Next we have Azure Logic app , that listens to the Azure service bus Queue at a 1 sec interval. It parses the message content in the queue and gets matchId & commentary.
- Now the parsed output is passed as an input to our Azure Prompt flow via a HTTP post call.

- MatchId is then passed onto a python code
4.1. It is used to fetch the match details from Azure CosmosDB - Concurrent users from the previous step is then passed onto the next python code
5.1. It is now used to fetch the scaling ladder configurations from Azure CosmosDB - Now we make use of all inputs from previous 3 steps to form the system prompt.
- GPT model act upon the prompt that we provided and outputs the JSON in the requested fomrat. It is then received by Azure Logic app
- & 9. Based on the output, we either increase/decrease the instance count of virtual machine scale sets in Video and Recommendation service.
4.4 Let’s brace for Tsunamis with GPT models

4.4.1 Step 1: Azure Prompt Flow
Pre-requisites
- Azure subscription
- Azure OpenAI subscription
- Azure Machine Learning studio
4.4.1.2 Create Flows in Azure Machine Learning Studio
- click on create button in the flows and select standard flow
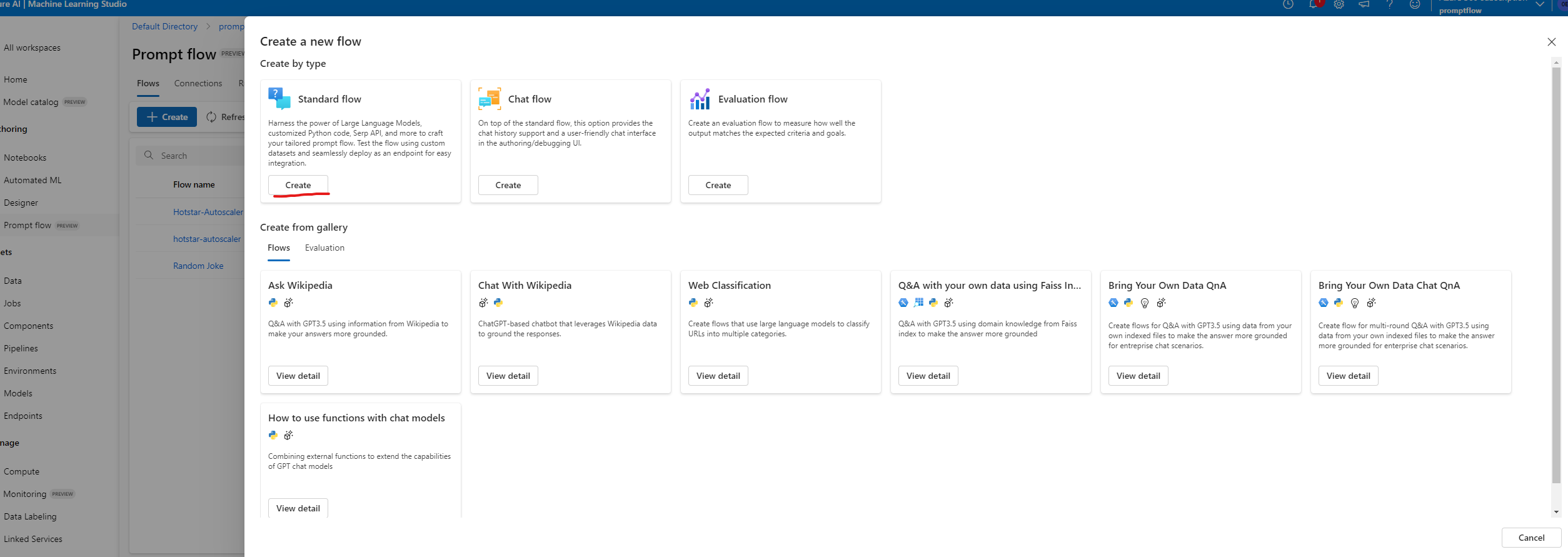
4.4.1.3 Create Connections
- Create connections for OpenAI and Cosmos as below
- Connections for Azure OpenAI is predefined in the connectors, however for Cosmos connection choose Custom.
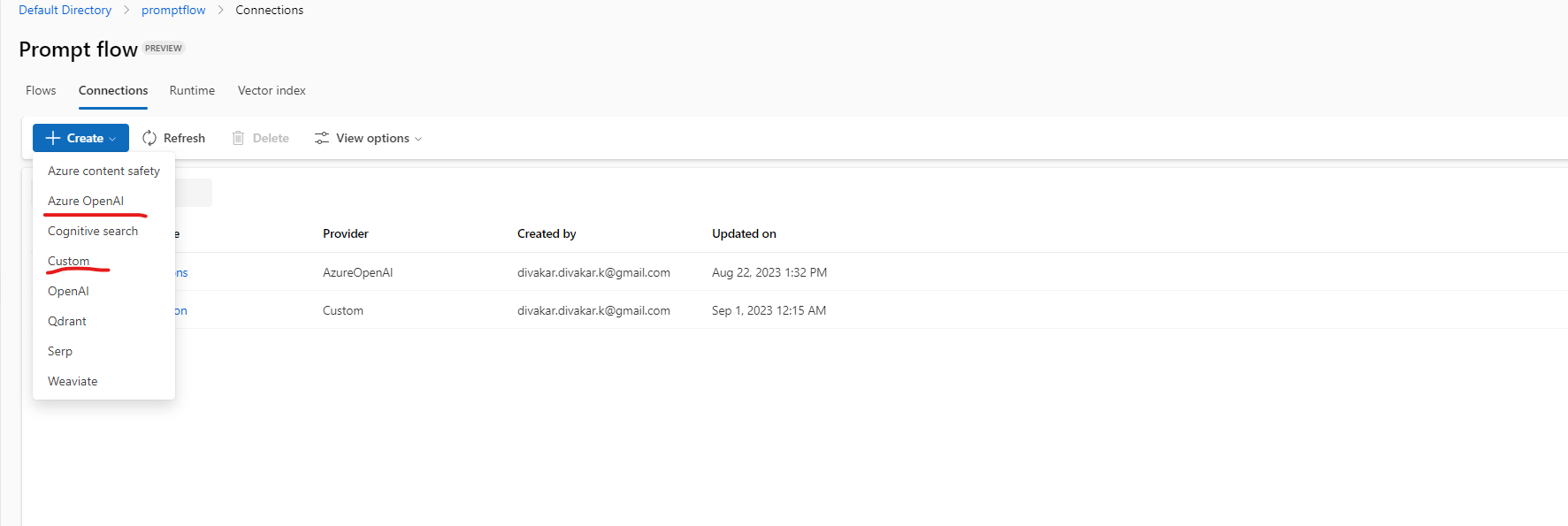
4.4.1.3.1 Azure OpenAI connector
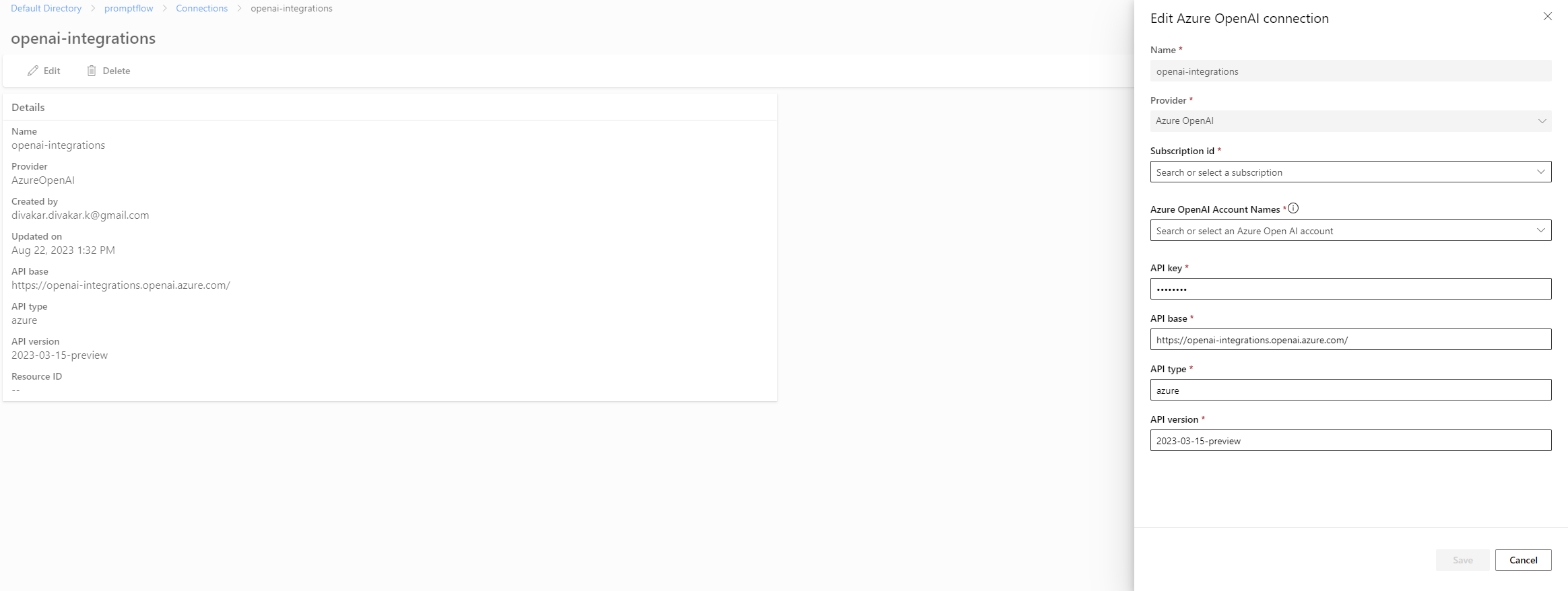
4.4.1.3.2 Azure CosmosDB connector
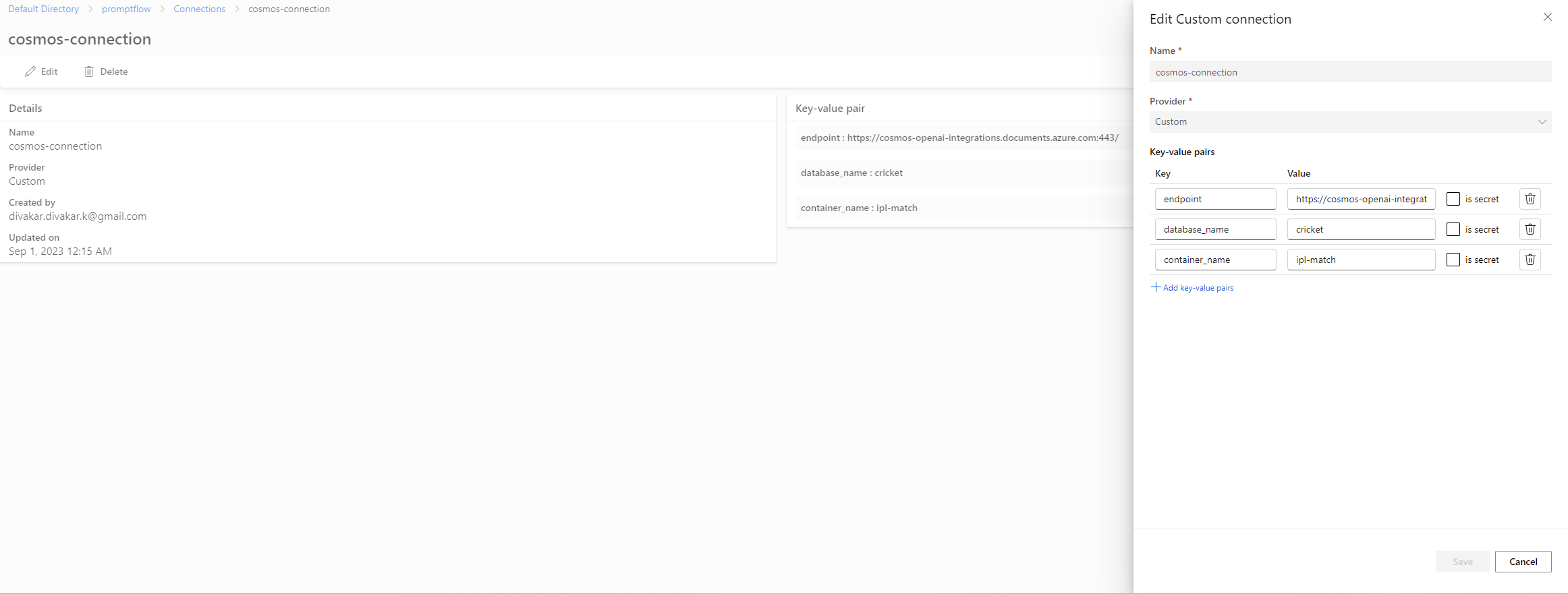
4.4.1.4 Create Custom Environments
- Now we need to custom environments for installing Azure Cosmos DB dependencies in the compute instance
- Provide a name for custom environment and Select Create a new docker context in the environment source dropdown
- In the next wizard, create as below
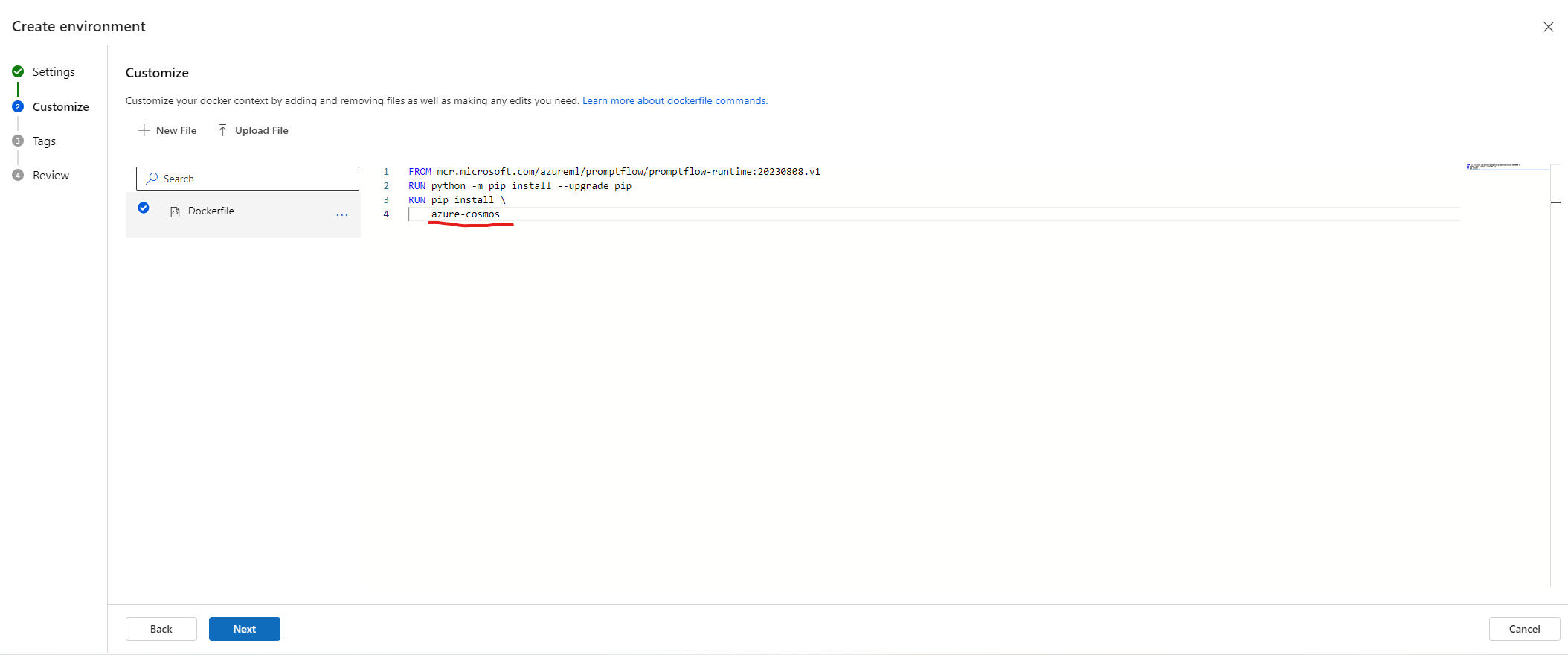
- Click Create button in the final wizard
4.4.1.4.1 Create Environment.yaml
- Once the custom environment is created , make a note of Azure container registry path.
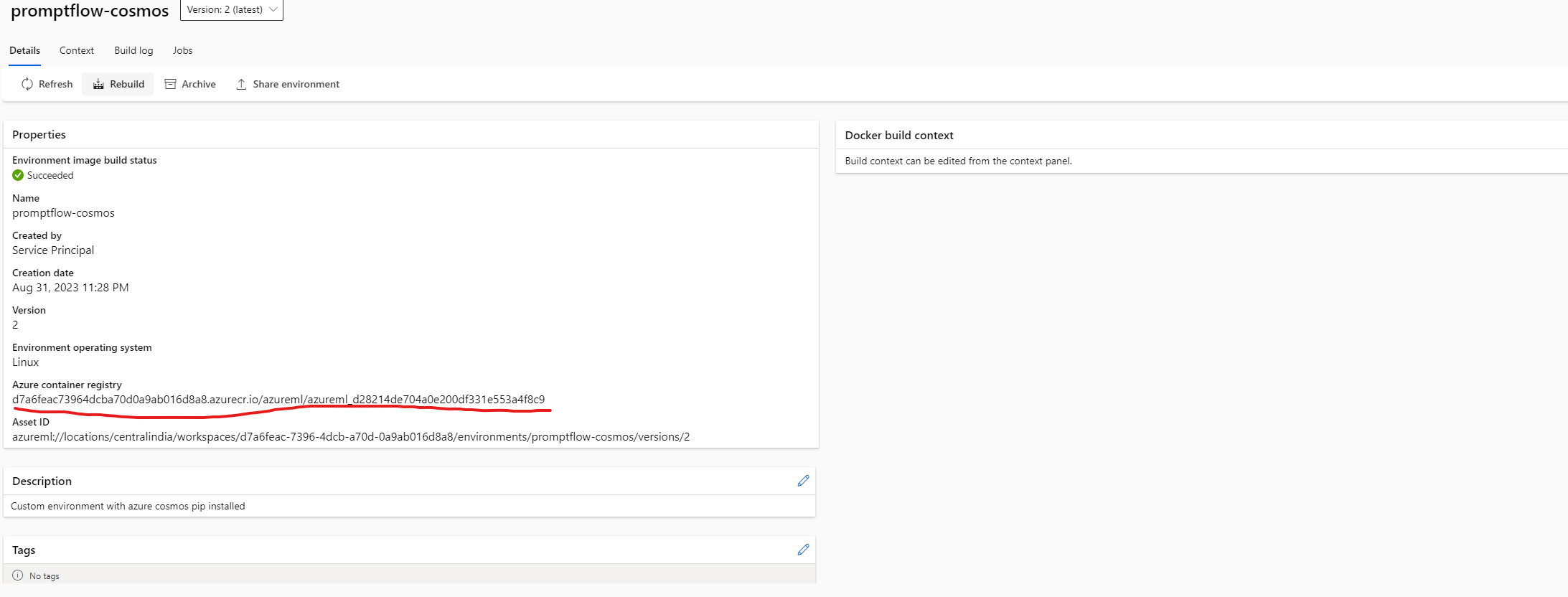
- Now Create the environment.yaml file as below
|
|
- Now create a new environment using Azure CLI command
|
|
4.4.1.5 Create Runtime
- Create a compute instance which is required for creating a Runtime in Prmopt Flow.
- Now next step is to create a Runtime on top of the custom environment we created via Azure Cli commmand.
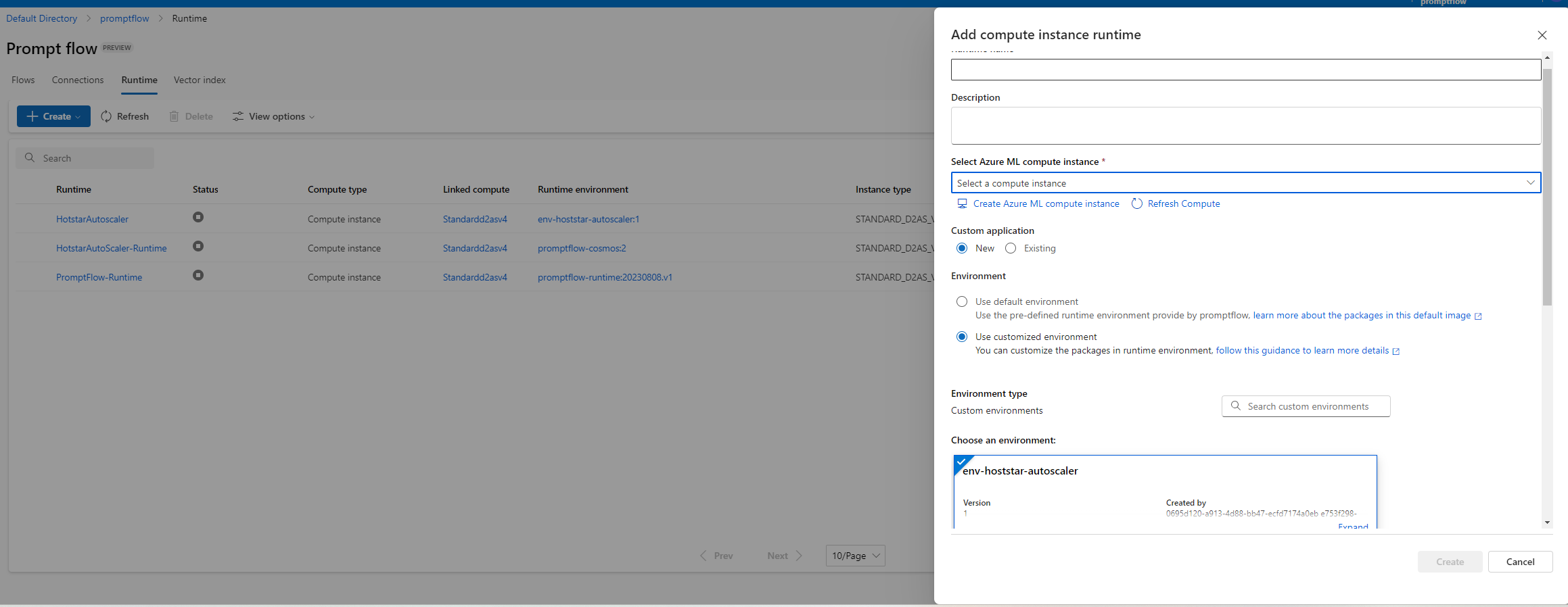
4.4.1.6 Add steps in Prompt Flow
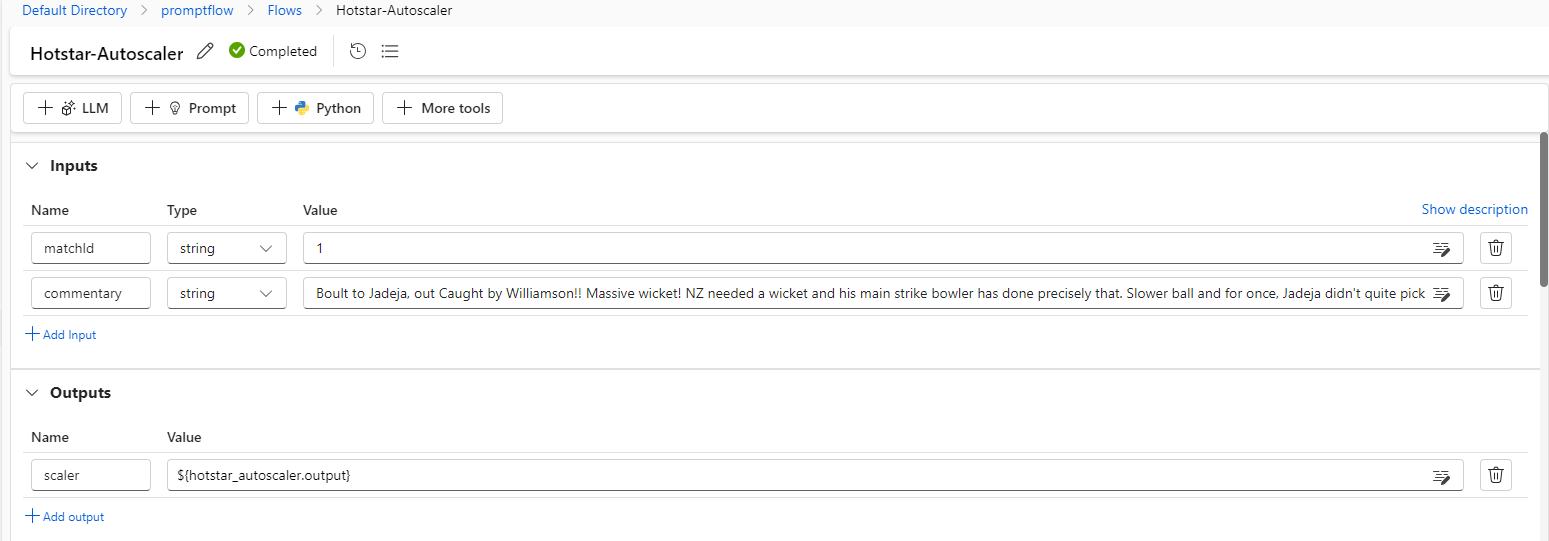
- Choose the runtime created in the previous step in the Flows
- Create 2 parameters for Inputs and output as below
4.4.1.6.1 Fetch match_details python code
|
|

4.4.1.6.2 Fetch scaling ladder configuration, it needs the concurrent users input from previous step
|
|
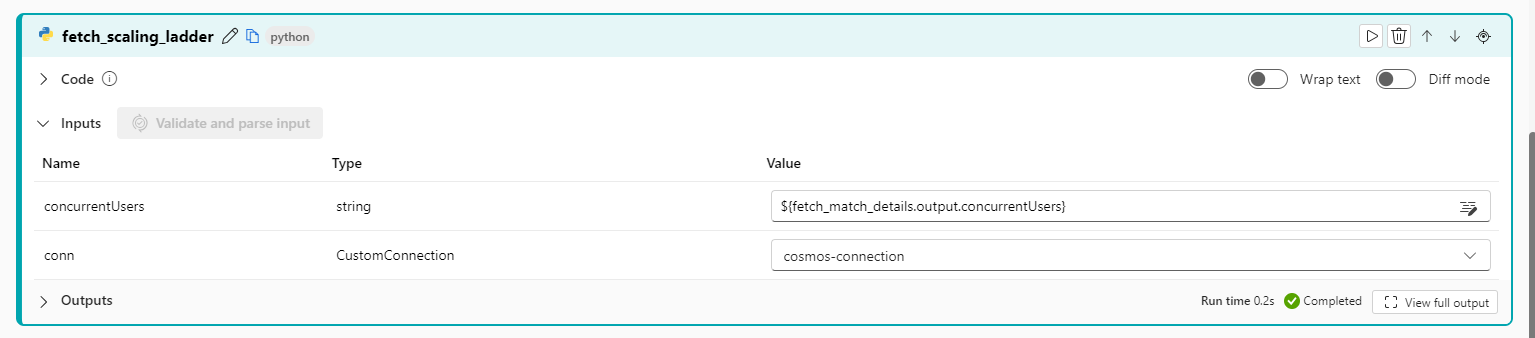
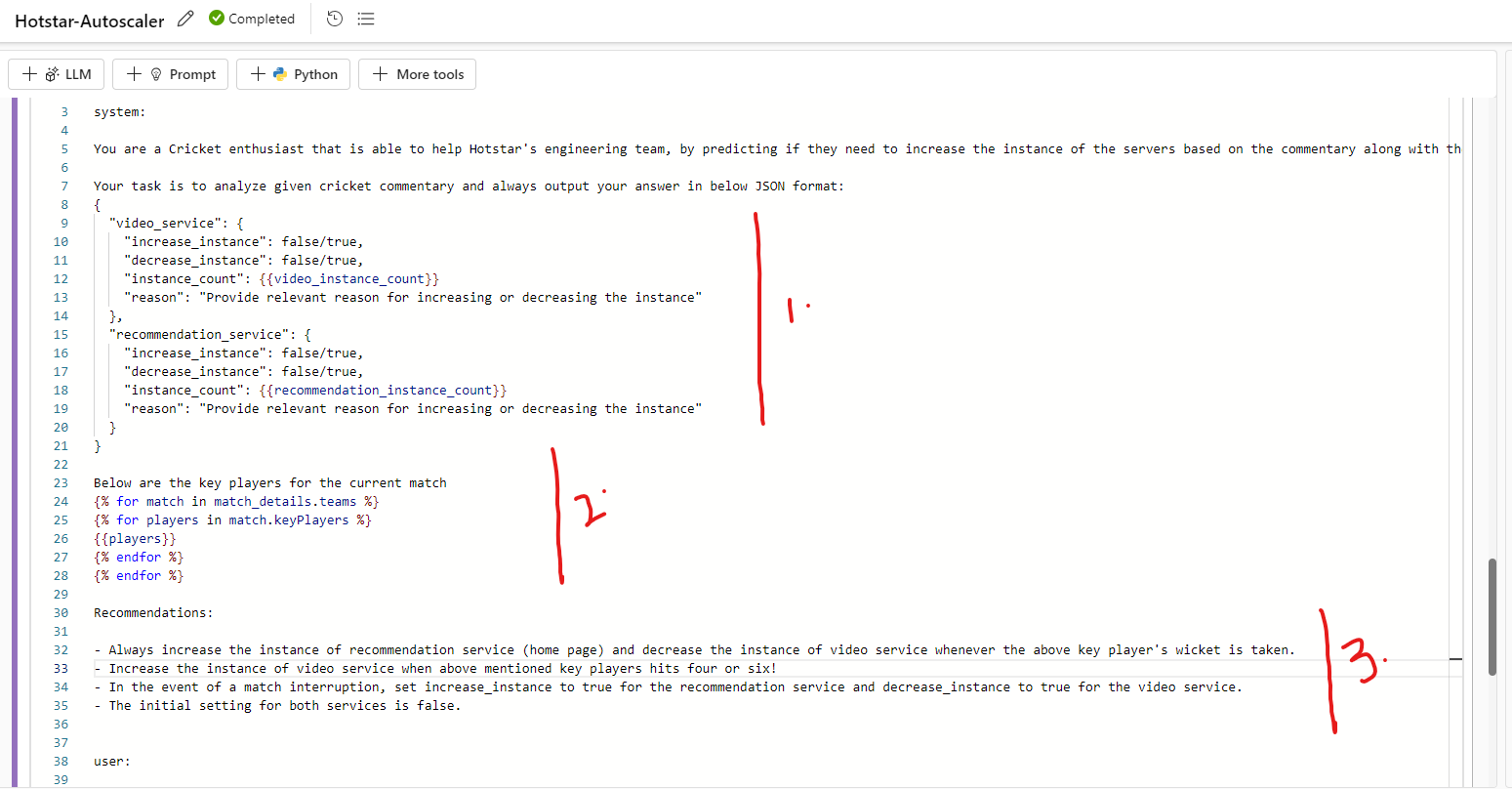
4.4.1.6.3 Define system prompt
- In the system prompt we set the behavior of the model
- Once it is done we break down 3 parts
- We will define the output JSON format
- We will loop through the key players of the match from both the teams
- We will provide recommendations for GPT model to follow
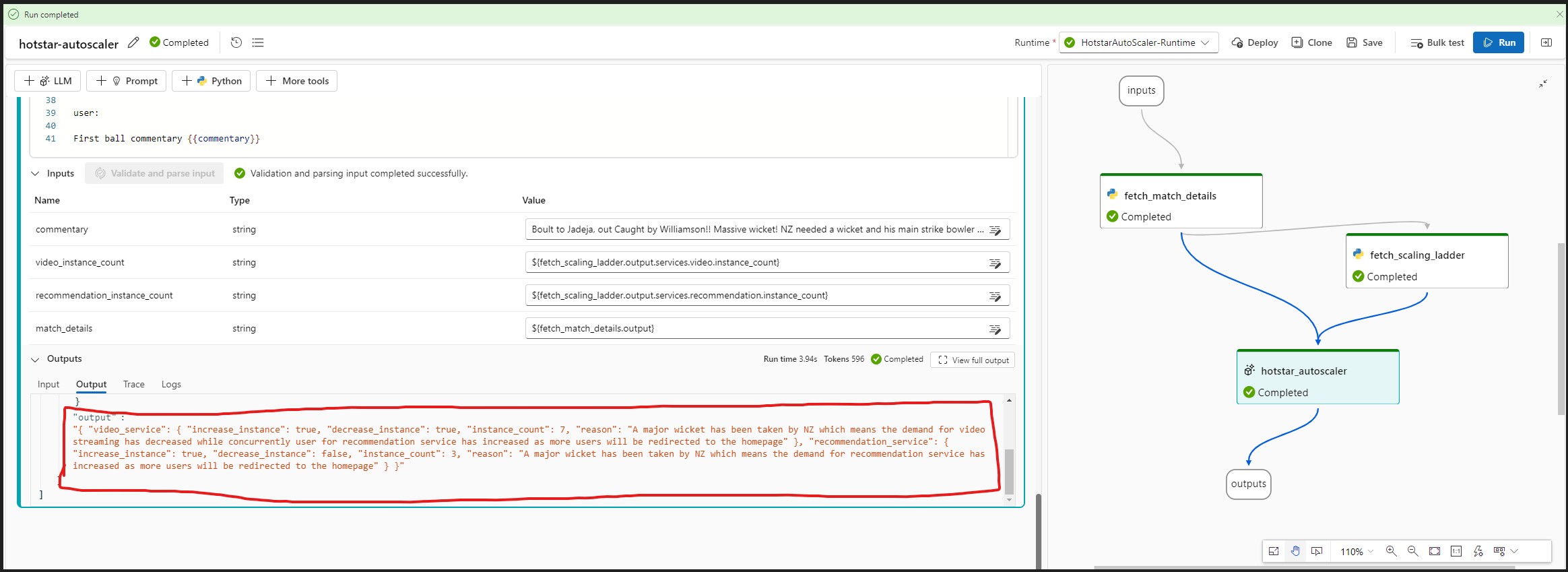
4.4.1.6.4 Let’s do a test run!
- Based on the prompt, model was able to provide almost the right suggestions. Except there is a mismatch in the flag of video service increase instance.
- We can however fine-tune the model to provide more acurate results. I will try to cover this in the next blog of this series.
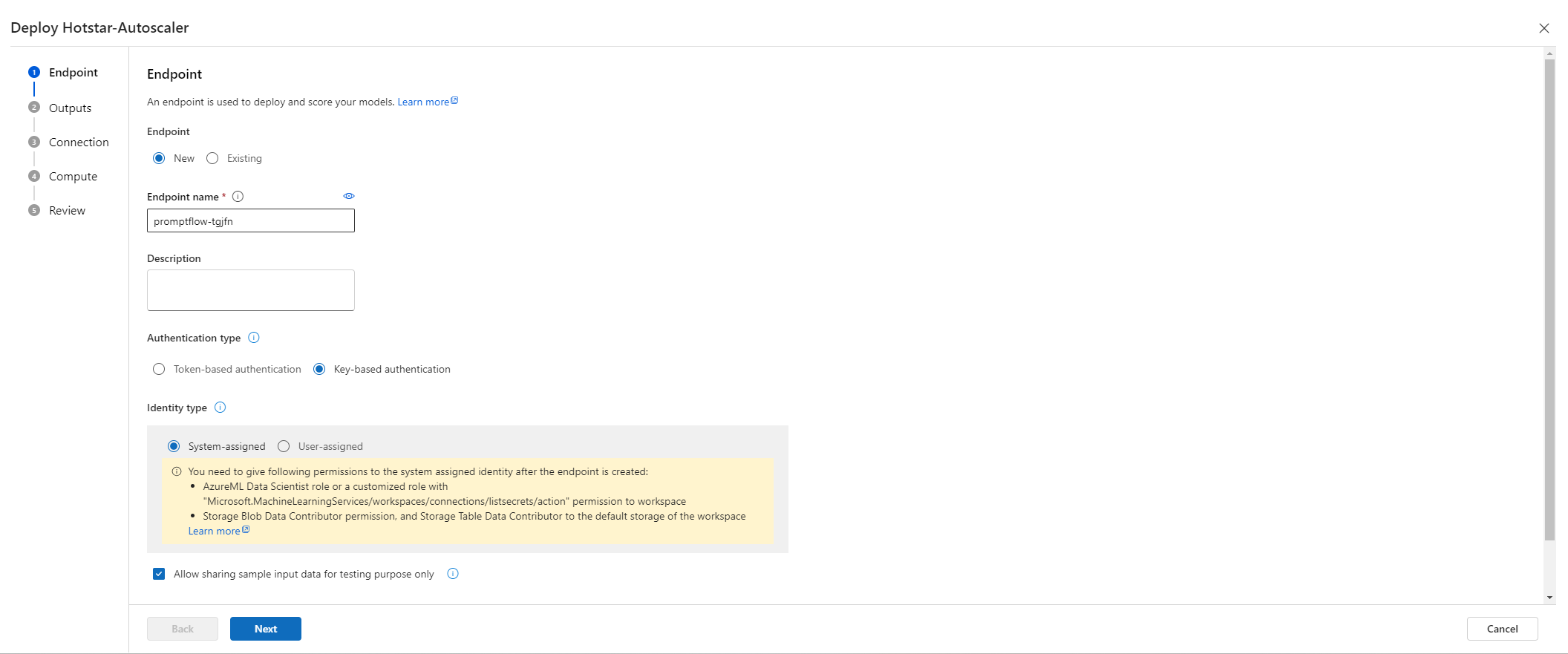
4.4.1.7 Deploy real-time endpoint
- Chose deploy button, it will popup a wizard
- In the first step, provide endpoint name, authentication type (key-based) and click on next button
- In the next step chose the output to include in the endpoint response
- After that verify the connection details provided in the Azure prompt flow, if needed modify the connections based on specific environments.
- Chose a comput instance
- Click on Deploy button
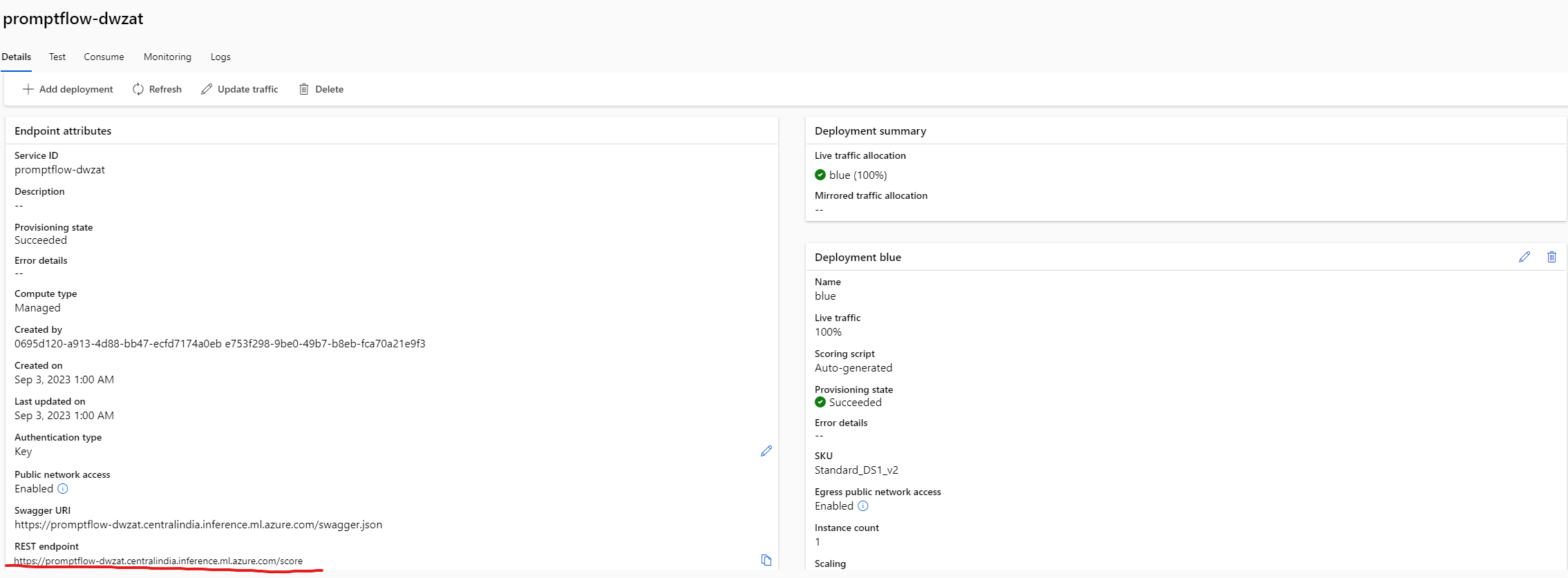
- Add AzureML Data scientist RBAC role to the endpoint created for accessing the workspace
- Make a note of key and the url for us to invoke it from Azure Logic apps
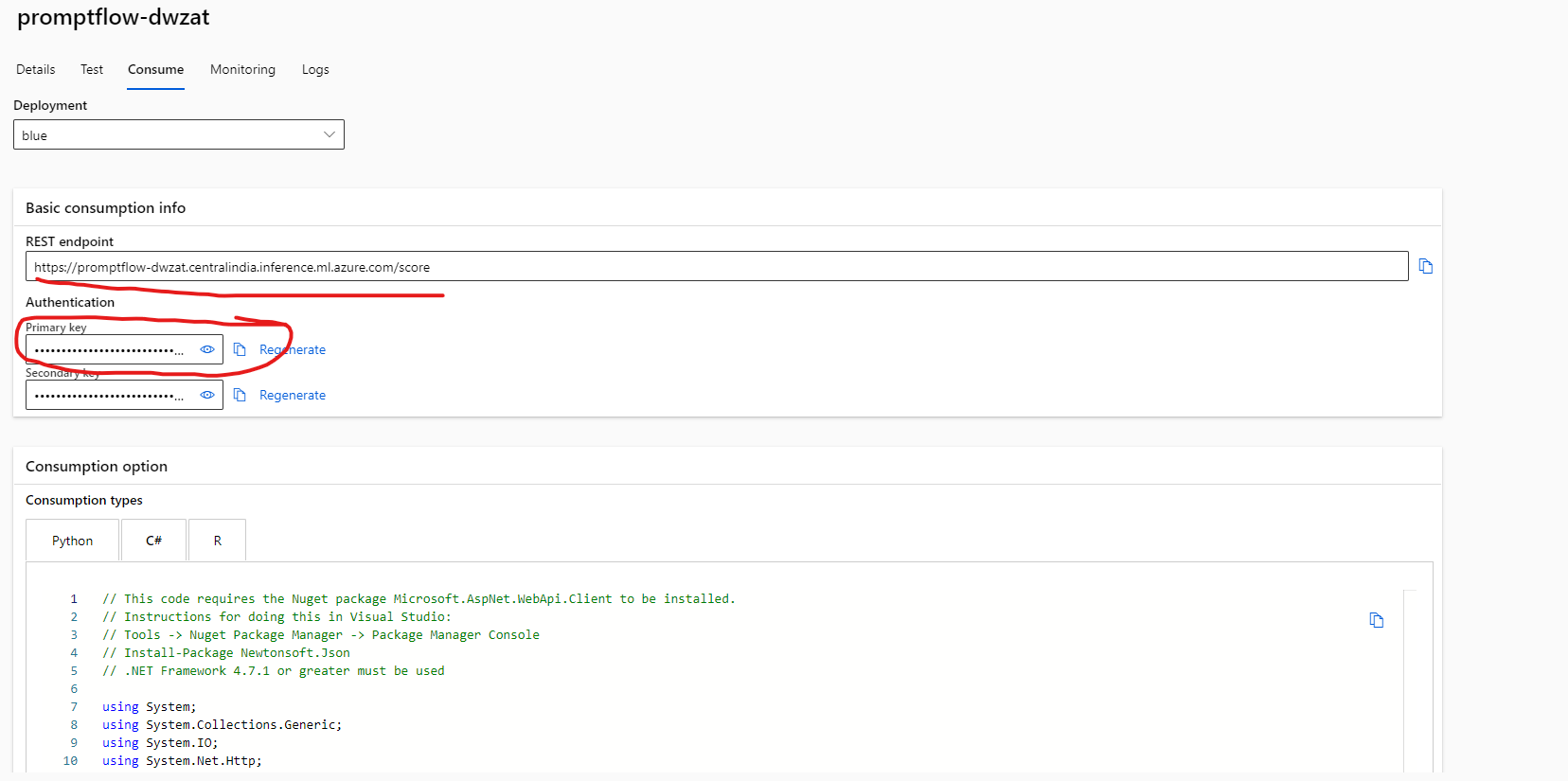
4.4.2 Step 2: Create Commentary service
|
|
4.4.3 Step 3: Create Azure Service Bus
- Create a Service bus namespace and a queue under it
- Copy the keys and use it in the above commentary service to establish the connection
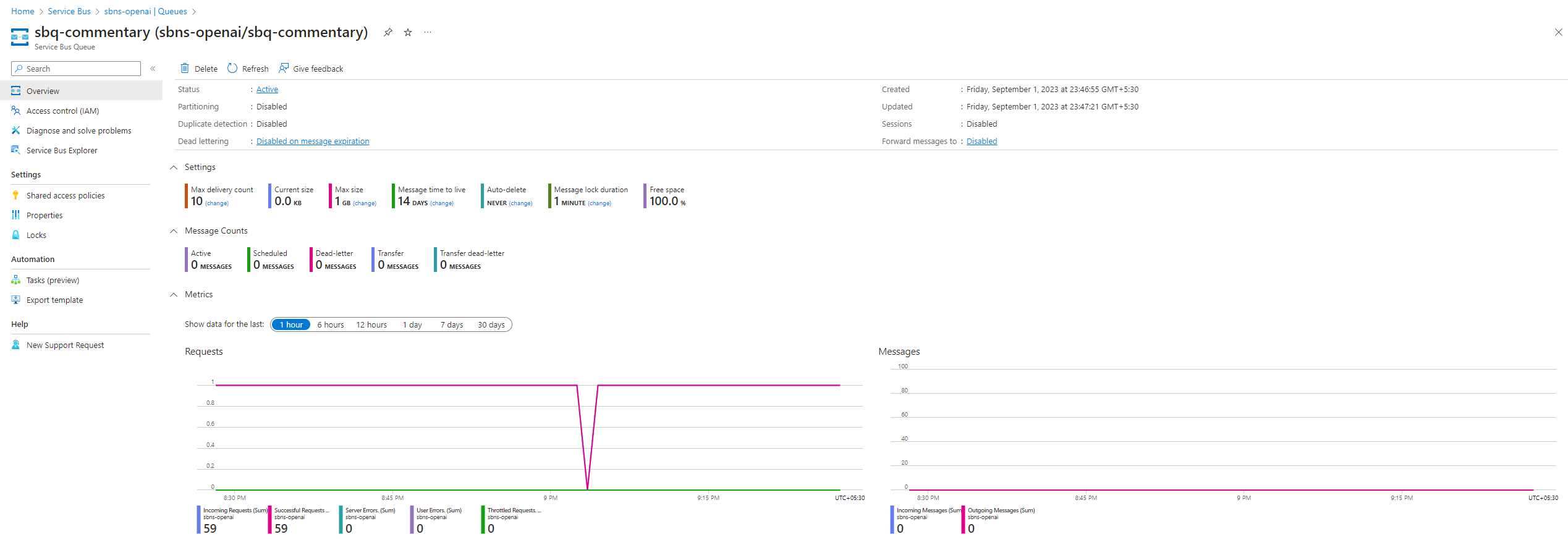
4.4.4 Step 4: Create Azure Logic Apps
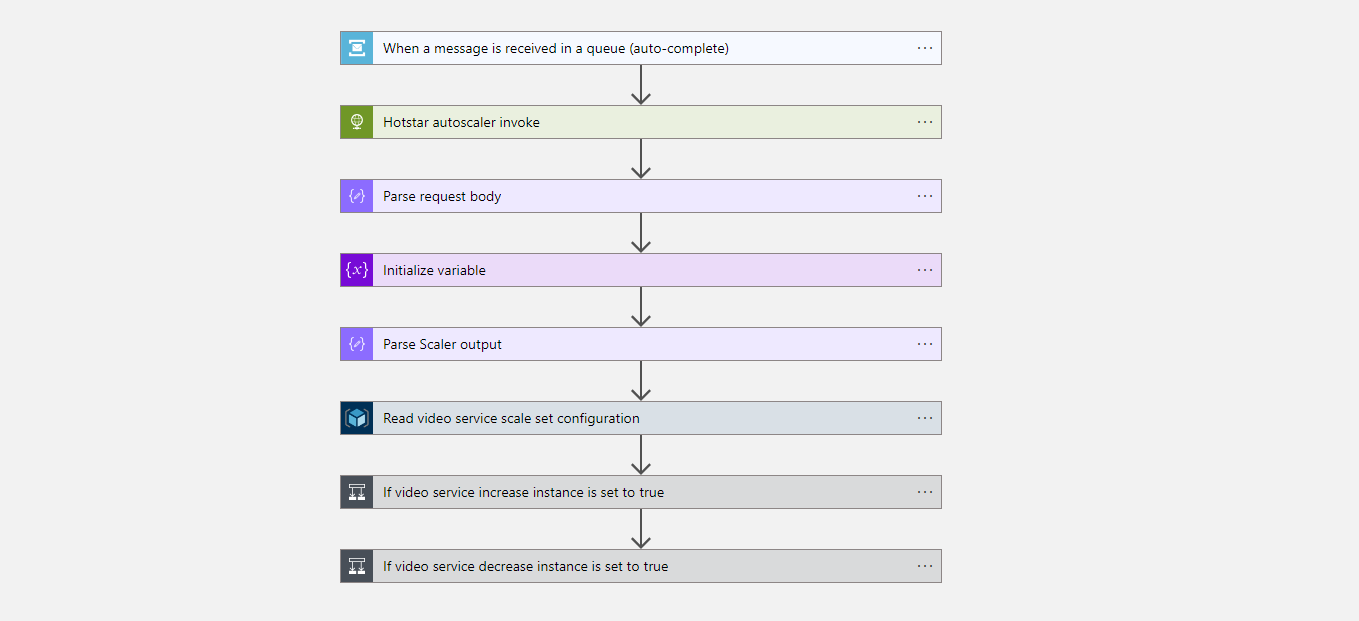
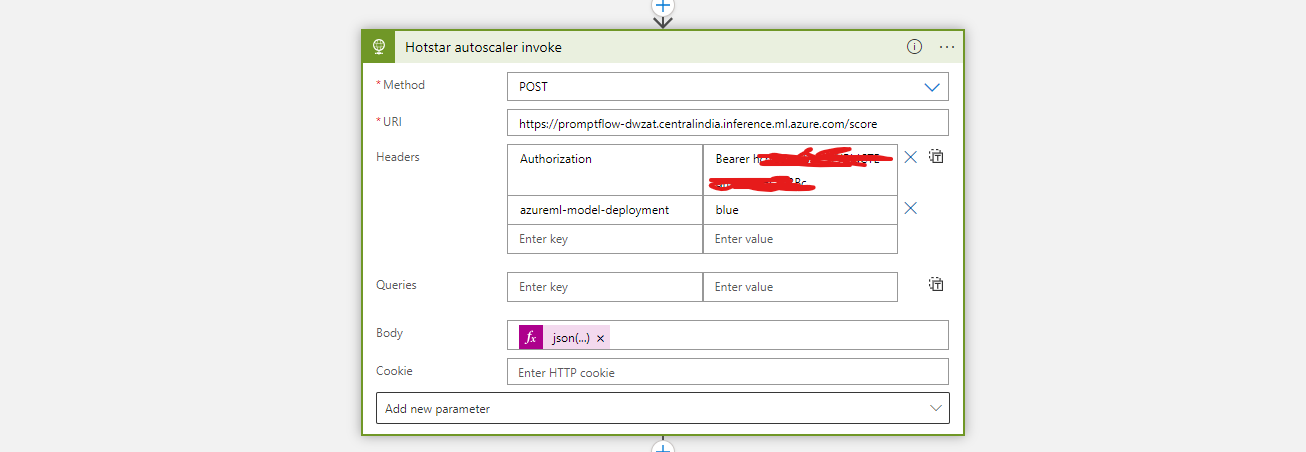
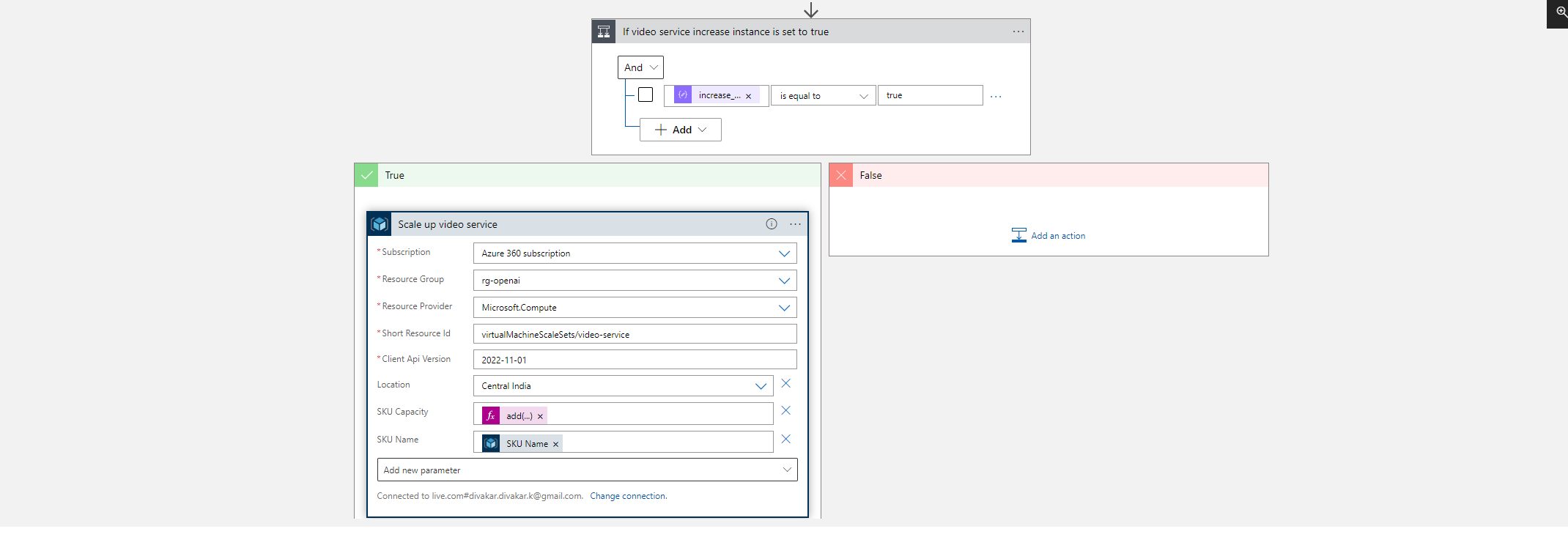
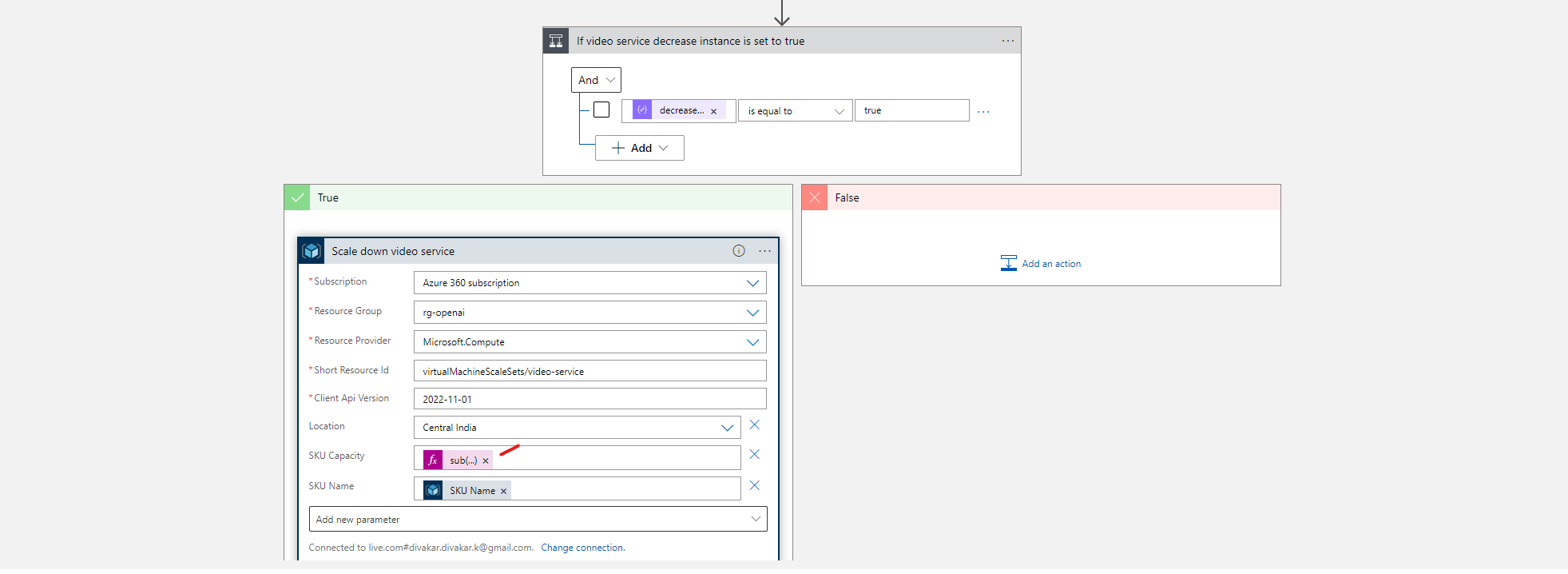
4.4.5 Step 5: Create Virtual machine scale sets
- create virtual machine scale sets for both video and recommendation service
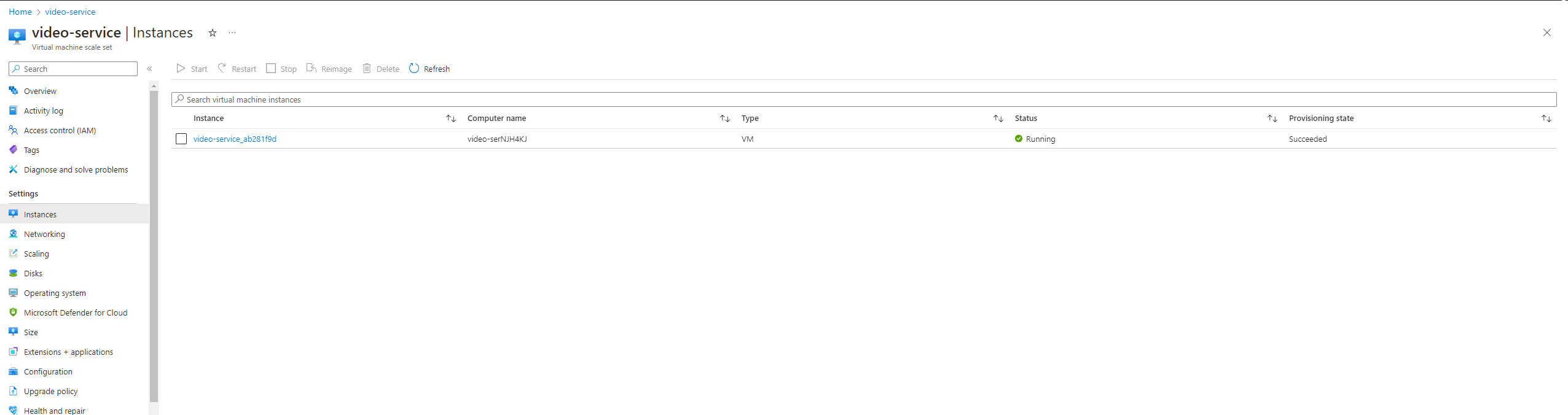
4.4.6 Step 6: Brace for Tsunamis!
- Run the Commentary service and initiate the process of a simulated hotstar environment
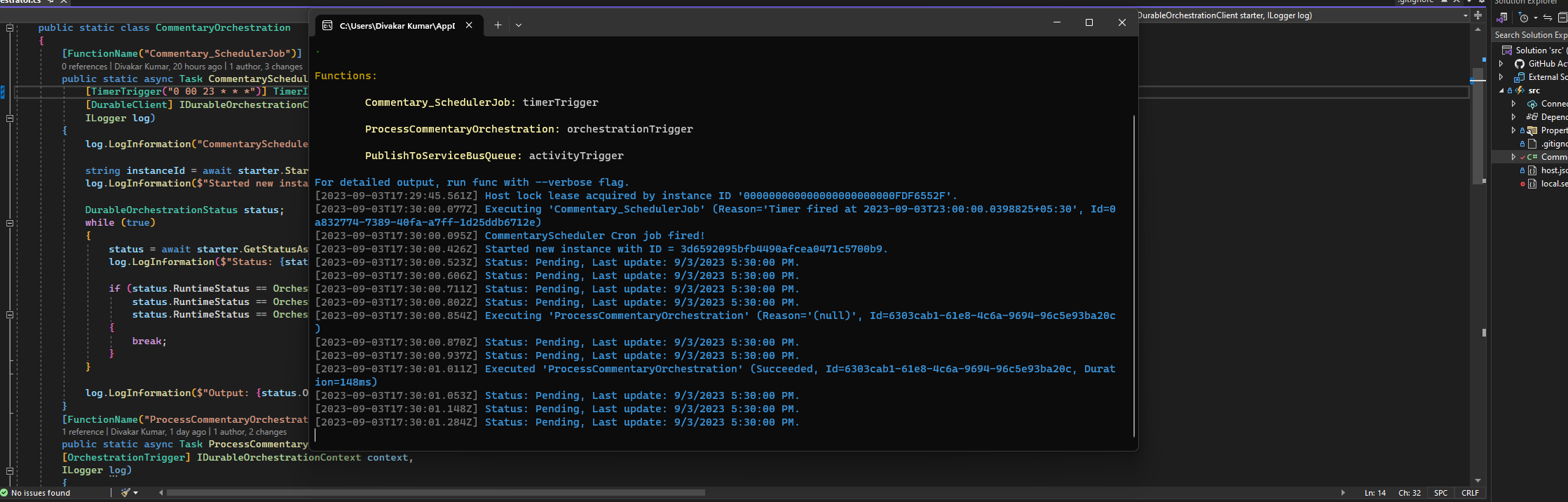

5 Special thanks
- Nikhil Sehgal - despite being the CEO and founder of a company, took the time to address the questions and uncertainties I had.
6 References
7 Upcoming blogs in this series
-
I have encountered few inaccurate results in the logic app runs, with some outputs not aligning with our expectations. Therefore, in the upcoming blog, we will explore the process of fine-tuning these models to provide more precise and reliable results.
-
Following that, let’s explore how to pre-warm these instances under specific scenarios. For instance, we can monitor the recent commentary history to assess the current batsman’s performance. If there’s a high probability that the current batsman will be dismissed soon, and the next batsman is a key player, we can strategically pre-warm the instances in advance.
-
Additionally, we can introduce other models like Llama2 and evaluate their results and performance in comparison to GPT models.
If you have any other topic to cover as part of this series. Please do let me know in the comments.
Sponsor
If you find this post helpful, please consider sponsoring.
